




إن أنظمة ترجمة الكلام إلى كلام (speech-to-speech) آخذة في التطوّر منذ عقود بغية مُساعدة الناطقين بلُغات مُختلفة التواصل فيما بينهم، لكنّ عملية الترجمة هذه تمرُّ عادة في ثلاث مراحل أساسية منفصلة:
– التعرف التلقائي إلى الكلام (automatic speech recognition)؛ لتحويل الكلام إلى نص وسيط مكتوب.
– الترجمة الآلية (machine translation)؛ لترجمة النص الوسيط المكتوب إلى اللغة المقصودة.
– تركيب الكلام (text-to-speech synthesis)؛ لتوليد الكلام في اللغة المقصودة استنادًا إلى النص المُترجَم.
في الواقع، يُعَدُّ التقسيم ناجحًا بالفعل واعتمدت عليه أنظمة ترجمة الكلام إلى كلام ومن بينها مُترجِم غوغل؛ لكن الحاجة المُلحة إلى تقليل الكلفة ورفع الأداء تدفع بمراكز الأبحاث إلى التطوير المُستمر وابتكار تحسينات فريدة من نوعها لتحقيق الغاية المنشودة.
يقترحون -في الورقة البحثية هنا المنشورة حديثًا- نظامًا تجريبيًّا جديدًا أطلقوا عليه: Translatotron، يستندُ إلى أنموذج تسلسلي (sequence-to-sequence) وحيد من شأنه الترجمة المُباشِرة إلى الكلام دون التعويل على تحويله إلى نص وسيط والمرور بالمراحل المذكورة آنفًا.
ومن الميزات المُهمة للأنموذج المُقترَح: سرعة الاستدلال الأكبر نسبيًّا، وتجنُّب الأخطاء المُترتبة على مرحلتَي التعرف والترجمة؛ مما يُسهِّل الحفاظ على سمات صوت المُتكلّم الأصلي في الترجمة، ويجعل التعامل أفضل مع الكلمات التي لا تحتاج إلى ترجمة، مثل الأسماء.
كيف بدأت رحلة Translatotron؟
كانت بداية ظهور النماذج المُباشرة (end-to-end) في سياق ترجمة الكلام في عام 2016 ميلادية، حين أثبت الباحثون نجاعة استخدام أنموذج (sequence-to-sequence) وحيد لترجمة الكلام إلى نص (speech-to-text) ترجمة فورية بالاستعانة بمدوّنة (corpus) صغيرة للترجمة بين اللغتين الإنجليزية والفرنسية. تتمثل الفكرة هنا في استخدام المدونة في ترجمة الكلام المنطوق في لغة مُباشرةً إلى نص مكتوب في لغة أخرى، دون المرور بمرحلتَي التعرف إلى الكلام (تحويله إلى نص) ثم ترجمة النص إلى اللغة المقصودة.
وفي السنة التي تليها، نُشرت ورقة أخرى تقترح أنموذج شبكة عصبونية تكرارية لترجمة الكلام إلى نص أيضًا، وتُثبت تفوق النماذج المُباشرة على التسلسلية. وقد اختبرتها (Linguistic Data Consortium: LDC) على تسجيلات (fisher spanish speech) المجانية والمطورة، التي تتضمن 163 ساعة من المُحادثات الهاتفية لنحو 136 شخص من الناطقين -الأصليين وغير الأصليين- باللغة الإسبانية.
بُذلت جهود لا يُستهان بها بغرض تحسين طرائق ترجمة الكلام إلى نص؛ لكن (Translatotron) يتقدَّم خطوة إلى الأمام في استخدام الأنموذج التسلسلي الوحيد في مساق أبعد من ذلك لتكون ترجمة الكلام إلى الكلام مباشرة.
إذن؛ يستند المُترجم إلى أنموذج تسلسلي دخله هو طيف الإشارة الصوتية للكلام المَحكي باللغة الأصلية، ليولد طيف الإشارة الصوتية للكلام المنطوق باللغة المقصودة. ويستخدم مكوّنين مُدربين استخدامًا مُنفصلًا هما: شبكة عصبونية بمثابة مُشفر صوتي (vocoder) يحوّل طيف الإشارة الناتج إلى أمواج صوتية (waveforms) في المجال الزمني، إضافة إلى شبكة أخرى بمثابة مُشفر لصوت المُتكلم (speaker encoder) اختياري؛ للحفاظ على طابع الصوت الخاص بالمُتكلم الأصلي في الصوت المُولَّد.
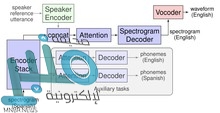
آلية الحفاظ على طابع/ سمات صوت المُتكلم:
إن الشبكة العصبونية التي تُعنى بتشفير صوت المُتكلم إضافةٌ اختيارية للحفاظ على طابع صوت المُتكلم، إلا أنها ضرورية لإضفاء الدقة وطابع الواقعية على نتيجة الترجمة.
لتحقيق هذه الخاصية، تستفيد غوغل من الأبحاث السابقة المُجراة في مراكزها البحثية؛ إذ إن الشبكة المسؤولة عن تشفير كلام المُتكلم مُدربة مُسبقًا ضمن مشروع التحقق من المُتكلم هنا (speaker verification) التي استُخدمت بدورها ضمن مشروع توليد الكلام لعدة مُتحدثين هنا .
تقييم (Translatotron):
على الرغم من أن (Translatotron) يُعد الأول من نوعه على الإطلاق في ترجمة الكلام المحكي بلغة مُعينة مباشرةً إلى كلام محكي بلغة معينة أخرى، وبصوت المُتكلم الأصلي نفسه، إلا أن نقاط ضعفه غير خافية عن العيان؛ إذ إن النتائج ليست مثالية وقد تكون الترجمة ركيكة أو منقوصة؛ نظرًا إلى أنه يترجم الصوت إلى صوت دون استخدام أي عمليات مُعالجة متوسطة.
لكن؛ لا يخفى عليك ما يختصره هذا المنهج من مراحل الترجمة -التي ذكرتها في بداية المقال- والمتسببة في إضعاف جودة الكلام النهائي إضعافًا واضحًا.
أضف إلى ذلك، اختُبِر المُترجم على ترجمة اللغة الإسبانية إلى الإنجليزية فقط، والتي تُعاين أمور مواءَمتها للأنموذج وما إلى ذلك؛ مما يتطلب مزيدًا من التجارب والاختبارات وتزويده بمزيد من الأمثلة والعينات.
لا يزال (Translatotron) إثباتًا للمنهَج الجديد؛ فكثيرٌ من الخطوات بالانتظار قبل إطلاقه مُنتجًا يستخدمه الناس والمطورين.






